

Some things are meant to be BIG: engagement rings, brothers, SATC characters, fish, cities, and Mac burgers. However, API payloads don’t always need to be one of these—just ask anyone who’s encountered an HTTP 413 Payload Too Large error when submitting a form or making an API request.
At Abstract API we believe that there’s always room for improvement. That’s why, we’ve updated our article on the HTTP 413 status code to offer a deeper dive into its causes, implications, and solutions.
Keep on reading to discover everything you need to know about this HTTP status code.
What is the HTTP 413 Payload Too Large Error?
HTTP 413 Payload Too Large status code indicates that the server is refusing to process a client’s request because the payload exceeds its predefined limits. In other words, the data you are trying to send or upload is too large.
Imagine someone asks you to read the entire Encyclopædia Britannica. Unless you’re incredibly fond of reading plain facts, you’d likely respond—perhaps not politely—that completing such a task is impossible. Similarly, when a server issues a 413 status code, it’s explicitly rejecting the request because the data is too large to process.
By doing so, servers avoid being overwhelmed by processing excessive data, especially when their resources are limited, or when they’re designed to handle smaller payloads. However, HTTP 413 errors are mostly caused by a mistake on the client’s part. Thankfully, they are easy to resolve by either reducing the data size or contacting the server administrator to increase the payload limits, among other measures.
To make things even simpler, a 413 status code might include a Retry-After header to indicate when the client can retry the request. Nonetheless, this is not a standard 413 error practice, despite being a user-friendly measure.
HTTP 413 errors are quite common, as many users are unaware of their causes and how to prevent them—unless the software is designed with payload size limits in mind and provides clear documentation on these limits (as Abstract API’s APIs do).
Therefore, understanding how to handle HTTP 413 errors—both to resolve issues you might trigger and to design your software to prevent them—is a key part of every programmer’s toolkit.
Causes of HTTP 413 Errors
As mentioned earlier, HTTP 413 errors typically occur due to honest, often unintentional, client mistakes—most commonly when a request exceeds the server's allowed size. But what exactly causes a request to surpass the server's limit? Here are some common causes:
- File upload exceeds server’s limit: The 413 status code is frequently issued when a client attempts uploading a file that is too large for the server's maximum allowed size. If you’ve ever failed to upload large images or video files to a website because they were excessively large, you'll probably know what we mean!
- Large form submission: Submitting a form with too many fields or very long text inputs greatly increases the payload size, challenging the server’s ability to process it. Excessively large text inputs, documents, or unnecessary fields often lead to a server’s inability to handle the request.
- Oversized API request: A common cause of HTTP 413 errors is sending an API request that exceeds the server's limit. Large JSON or XML objects can easily reach the API’s payload size restrictions, which typically range from 1 MB to 10 MB, depending on the server’s capacity, security considerations, and data processing needs.
- Cookie size: Web applications often store excessive data in cookies, such as user or session information, which makes them grow in size. Very large cookies sent to the server with each browser request can trigger a 413 status code. However, this is a relatively rare cause of Payload Too Large errors.
- Server configuration: A server’s configured limit may restrict incoming request payload sizes, triggering a 413 error once that limit is exceeded. These limits are often set in the application’s configuration (e.g., Node.js or PHP settings) or through web server software like NGINX or Apache.
- Compressed data size: While compressing data (e.g., zipping its content before sending it to the server) can optimize request size, decompression may cause the payload to exceed the server’s limit, leading to a 413 status code.
- Data encoding: Encoding methods such as Base64 (often used for images or binary data) can increase the size of the original data, potentially overwhelming the server.
- Third-party service limitations: Payment gateways, cloud services, or other third-party API integrations may impose additional payload-size limits, that can trigger a 413 error.
- Malformed requests: The presence of corrupt data or improperly formatted structures can lead to abnormally large requests which the server cannot process, returning a HTTP 413 Payload Too Large status code.
Impact on Users and Applications
HTTP 413 errors can have negative implications for both app developers and users. For users, it can be highly frustrating for users when they are unable to submit essential data required to complete processes such as sign-ups or file uploads on websites and media platforms. This feeling can become particularly vexing when the server does not return a user-friendly message explaining the error and how to fix it.
For developers, unsolved HTTP 413 errors can disrupt the functionality of applications that rely on large data transfers or uploads. When servers reject multiple requests from users, it can lead to drops in performance, ultimately breaking the app's functionality. Over time, such issues can harm the app’s reputation and erode user trust.
In the business context, broken application functionality can severely impact companies that rely on these apps to generate revenue. Reduced customer satisfaction caused by these errors can further damage the business’s bottom line.
Additionally, HTTP 413 errors are directly linked to API integration failures, which can cause data desynchronization and inhibit communication between services. Understanding API request validation and proper data handling is key to prevent integration errors, even with APIs designed to minimize HTTP 413 likelihood, such as Abstract API’s.
An even more frustrating scenario is one that many internet users have experienced—filling out a long form or waiting for a large document to upload, only to lose everything because the server couldn’t process the request and the app didn’t save your progress.
Fortunately, there’s good news: you can minimize the impact of HTTP 413 errors by addressing the issue on both the client and server sides. Keep reading to learn some strategies to do it, step-by-step.
Solving HTTP 413 Errors
Managing HTTP 413 errors is essential for maintaining an application’s functionality and ensuring a seamless user experience. Most causes of HTTP 413 errors can be resolved by applying practical, straightforward solutions. Here’s a breakdown of the most effective ones:
Client-Side Solutions
HTTP 413 errors can be addressed on the user’s end. In many cases, the HTTP 413 status code response will include a brief description of the issue, offering guidance on how to resolve it. However, client-side solutions can also be applied as preventive measures to ensure that the data being sent complies with the server's size limits.
Reduce File Size:
A common client-side solution for resolving HTTP 413 errors is compressing images and text data or using smaller file sizes. Compression removes unnecessary data, allowing large images to be uploaded without significantly reducing visual quality. Similarly, limiting file sizes helps prevent performance issues caused by oversized payload requests.
Client-side libraries like browser-image-compression can be used to compress images. To optimize images before sending a request, you can run the following code:
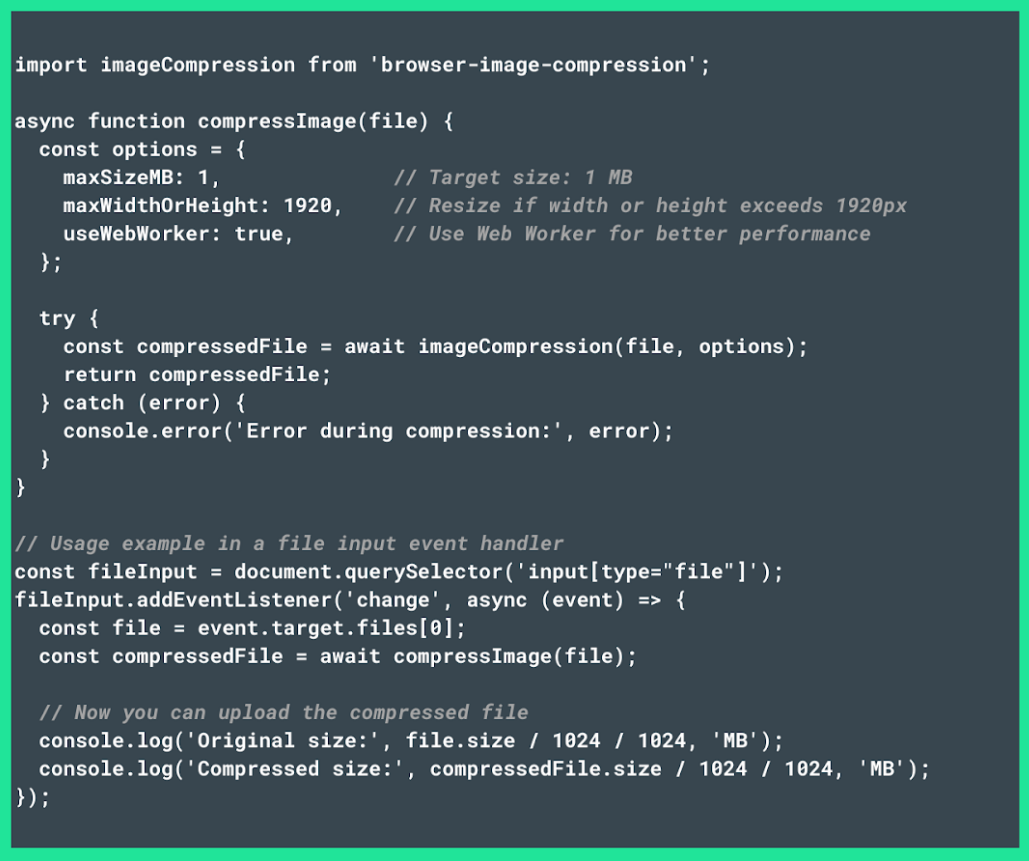
To modify the maximum file size, you’ll need to set the maxSizeMB attribute to a value supported by the server. In this case, it’s set to 1 MB.
If the image’s dimensions exceed the specified limit, the maxWidthOrHeight attribute will resize it. In this case, it will reduce the image to 1920 pixels.
Alternatively, you can use Python’s Pillow Library to programmatically resize images in web backends. Here’s a sample script you can run:

In this script, the max_size attribute defines width and height limits (here, set to 800x800 pixels). The optimize=True option compresses the image when saving it. The quality=85 parameter adjusts the compression level at 85%, reducing file size and image resolution. All of this makes the file smaller and lighter, easing the upload process.
Limit Form Fields
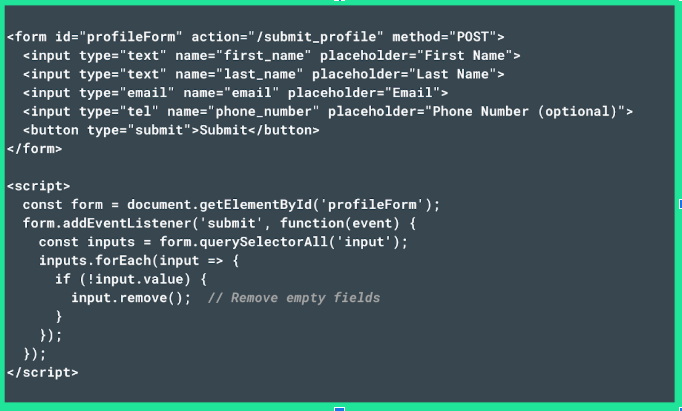
Another way you can resolve HTTP 413 errors is by reducing the number of form fields to only critical ones. This not only helps prevent errors but also improves user experience by making forms easier to complete. For example, a simplified form might look like this
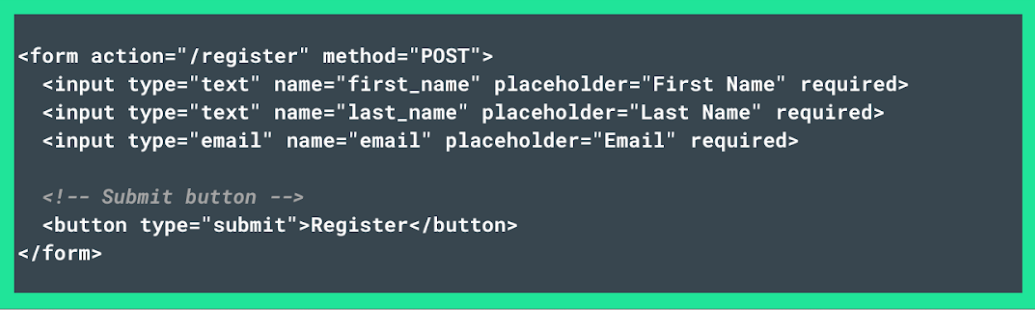
In this example, the form is streamlined, featuring only the fields for First Name, Last Name, and Email.
Additionally, limiting the length of text inputs prevents large form submissions that can trigger HTTP 413 code status. You can do this directly in HTML by setting the maxlength attribute.
Suppose, for instance, that you want to set the maximal input of a comment form to 500 characters. In such case, you can run the following script:
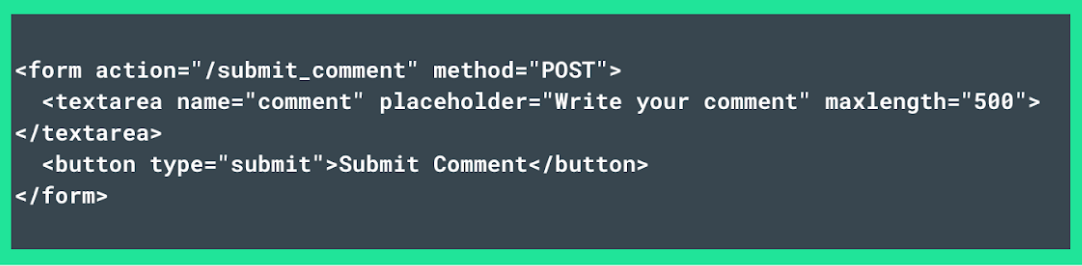
To enforce dynamic text limits and provide real-time feedback, you can add JavaScript to the HTML. This will ensure users are aware of the character limit before submitting the form.
The script below includes a live character counter that updates as the user types (e.g., 0 / 500 characters). As in the previous example, the maxlength attribute sets the character limit to 500.
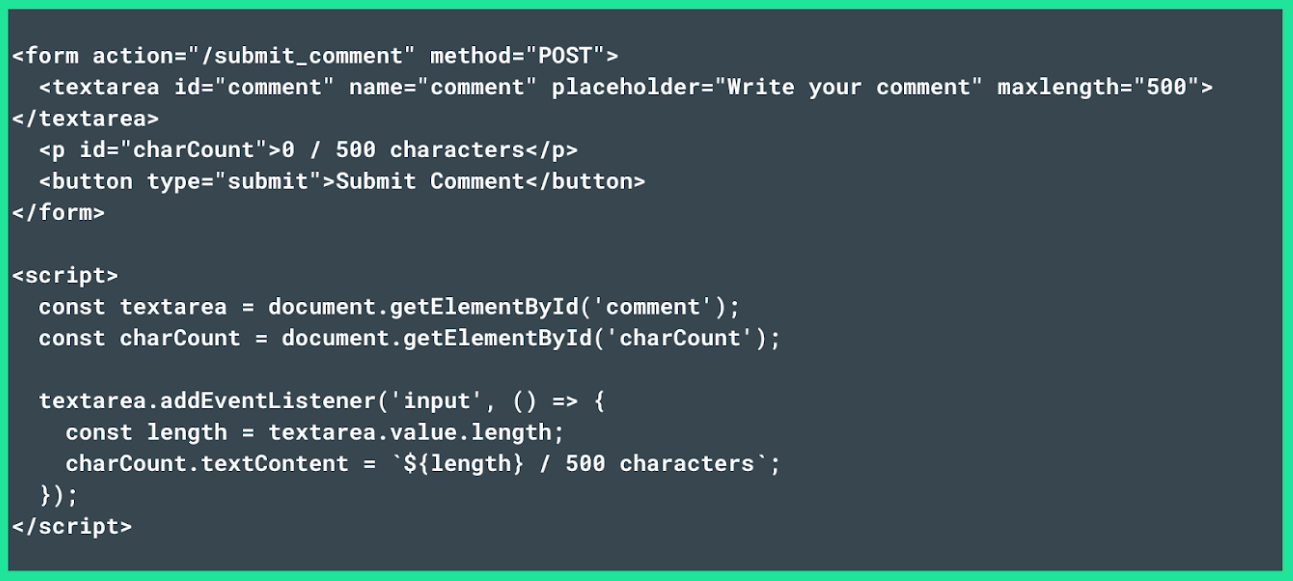
A third way to optimize form uploads and reduce data size is by removing empty optional fields before submitting the form. This can be done using the following JavaScript code:
Chunked Uploads:
When too large payloads cause API errors, a common solution is to split the payload into smaller chunks and upload them separately. This prevents the server from becoming overwhelmed and avoids exceeding the maximum allowed request size. Once all the chunks are uploaded, the server will process and reassemble them into the original file.
- On the client-side, you can use JavaScript to break a file into smaller chunks and upload them asynchronously. In the script below, the fileInput element allows the user to select a file through an input field.
- The CHUNK_SIZE = 5 * 1024 * 1024 means the file will be split into 5 MB chunks. When using this script, ensure the chunk size matches the server's maximum upload limit, which typically ranges from 5 MB to 10 MB.
- When you run the script, each piece will be uploaded to the server in a FormData object using a POST or fetch request. After one chunk is successfully uploaded, the next one will automatically begin to upload.
- Once all pieces have been uploaded, the server will merge them back into a single file by reading each chunk in sequence and writing the final file. If the process completes successfully, the server will send a confirmation to the client.
API Request Optimization:
To manage HTTP 413 errors, optimizing API requests when dealing with large payloads is essential. This is particularly important for applications that regularly handle significant amounts of data. Here are some strategies to reduce payload size and enhance API requests:
- Send only the necessary fields for a specific operation, instead of transmitting the entire data object. This can significantly reduce the payload size, solving HTTP 413 errors.
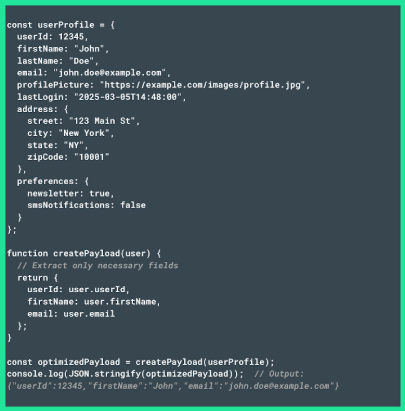
- Filter data before issuing the API request, ensuring it only contains the fields required. For instance, you can use a 'minimalistic' script that extracts just the critical data—such as user ID, name, and email. Here’s what that might look like

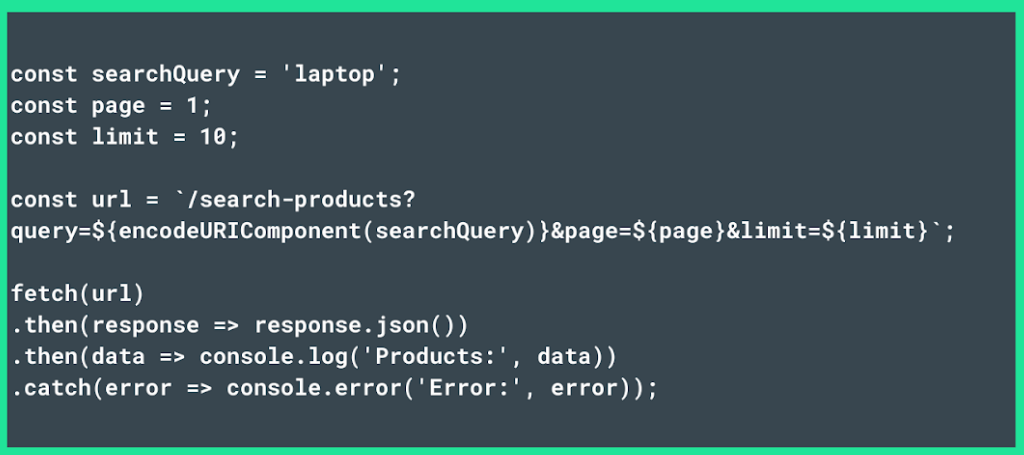
- Another way to optimize API calls is to use query parameters for GET requests. By following this approach, instead of sending data in the request body you will leverage query parameters to pass only the necessary information. This makes the request more efficient and reduces the risk of triggering an HTTP 413 error.
Below is an example of a script that passes only the search query, page number, and limit:
Server-Side Solutions
Another way to handle requests that exceed payload size limits is by implementing server-side solutions. That is, measures applied directly on the server to resolve HTTP 413 status codes.
While client-side solutions are more effective when users submit large forms or excessive data, server-side solutions are ideal for preventing resource overloads, and adjusting size limit configurations.
Increase Payload Size Limit
Setting the server’s request payload size limit to a higher threshold is a straightforward way to manage HTTP 413 errors. However, this comes with a downside: it can strain server resources (CPU, disk I/O, memory), potentially causing performance issues.
Therefore, before increasing the size limits, ensure your server can handle larger requests. Compressing large files and optimizing data can help servers with lower capacity process heavier requests more efficiently.
Adjusting payload limits differs depending on the server. Here’s how to modify them for different setups:
- Nginx: First you’ll have to locate the Nginx Configuration file, typically found at /etc/nginx/nginx.conf. Then, modify the payload size limit by setting the client_max_body_size directive. Save the changes, and restart Nginx to apply the new settings.
- Apache: Retrieve the Apache configuration file either from /etc/httpd/conf/httpd.conf or from /etc/apache2/apache2.conf. Adjust payload size by updating or adding the LimitRequestBody directive, specifying the limit value in bytes. After saving the changes, restart Apache to apply them.
- Node.js (Express): To increase the payload size limit in a Node.js (Express) application, use express.json() or express.urlencoded(). Keep in mind that default limits are 1MB for URL-encoded data, and 100kb for JSON requests. To apply the changes, simply run the express application after editing the request body limit.
Implement Request Validation
Server-side solutions address HTTP 413 issues more permanently, helping to prevent future occurrences. Validating requests on the server-side, in particular, prevents excessively large payloads from being processed, protecting your application from potential security breaches, and performance degradation.
With server-side validation, the server checks that the payload size complies with its limits. The request will only be processed if it meets these criteria; otherwise, it will be rejected straightforwardly.
Keep in mind that each server framework implements validation using different methods. Nonetheless, key general steps for server-side validation include:
- Defining reasonable request size limits, and enforcing them.
- Establishing which content types are allowed, and ensuring the server checks requests for compliance.
- Verifying headers such as Content-Length or Transfer-Encoding, which help determine payload size in advance.
- Inspecting request body size before processing. Especially, for large PUT and PATCH requests.
On the other hand, for specific server frameworks, you can manage request size limits in the following ways:
- Django: Configure maximum payload size by adjusting the DATA_UPLOAD_MAX_MEMORY_SIZE setting. When a request hits this limit, the server will raise a SuspiciousOperation exception.
- Node.js (Express): Limit body size through the express.urlencoded() and express.json() middleware functions. These offer a limit option that you can modify to set the maximum size the server will process.
- File uploads in Node.js: If you’re handling file uploads, use the Multer middleware to configure multipart/form-data request size limits.
- PHP-based applications: Set limits for file upload and payload size by configuring upload_max_filesize and post_max_size settings (found within php.ini).
Enable Compression on the Server
A third server-side solution for HTTP 413 errors is enabling compression on the server. Compression improves workflow efficiency by reducing bandwidth usage and lowering the chances of exceeding payload size limits. This is achieved by compressing both requests (client-to-server) and responses (server-to-client), ensuring smoother communication and data exchange.
To enable server-side compression for requests and responses, you can use algorithms like Brotli and GZIP. Once compression is activated, the client will send a request header (Content-Encoding: gzip or Content-Encoding: br), indicating that it can handle compressed data. Then, the server will automatically compress the requests and response body sizes.
The configuration of compression varies depending on the server. For instance:
- Apache offers GZIP compression for the response body. To set it up, you simply need to enable the mod_deflate module.
- Node.js (Express) provides the compression middleware for compressing responses, and less commonly, for compressing requests.
- Nginx supports GZIP compression, which by default, compresses only responses. However, it can be configured to compress requests as well. To enable compression, add the gzip on directive inside the http block of the nginx.conf file.
How to Prevent HTTP 413 Errors
Although HTTP 413 errors can be quickly resolved, their occurrence can still negatively impact user experience, application performance, and system scalability. Additionally, as previously mentioned, HTTP 413 errors pose a risk of data loss, especially if no backup or retry mechanisms are in place.
Consequences of failing to prevent such issues can include service abandonment, server overloads, blocked operations, and reduced conversion rates. This makes prevention a crucial step of dealing with HTTP 413 Payload Too Large errors.
To reduce the likelihood of encountering HTTP 413 errors, consider applying best practices such as enabling client-side validation, providing clear documentation on request size limits, and implementing robust error-handling mechanisms. Let’s explore each of these in detail.
Client-Side Validation to Prevent HTTP 413
We have already covered server-side validation as a method for managing HTTP 413 errors. Client-side validation works in a similar way by ensuring potential 413 issues are addressed before they reach the server.
However, with this validation type, overly large payloads are intercepted before they are sent. This provides real-time feedback to users, allowing them to quickly adjust their inputs and prevent HTTP 413 errors, workflow delays, and unnecessary server load.
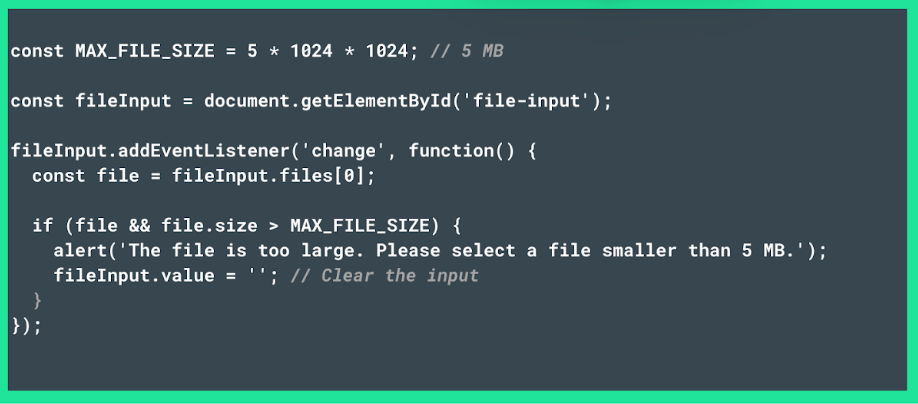
Client-side validation typically checks elements like file size and form field lengths. To implement it effectively, follow these steps:
- Start by limiting the number of items a request can have, using the MAX_ITEMS function on JavaScript.
- Use the validateItems function to ensure the number of items complies with the set limit, either blocking or allowing submission based on the result.
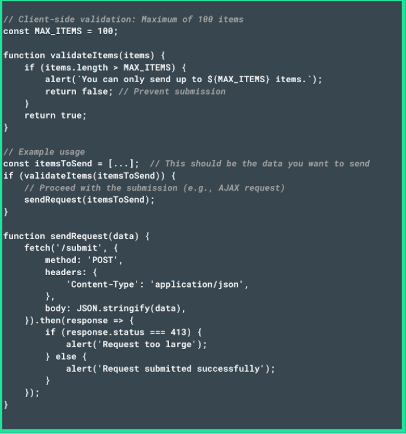
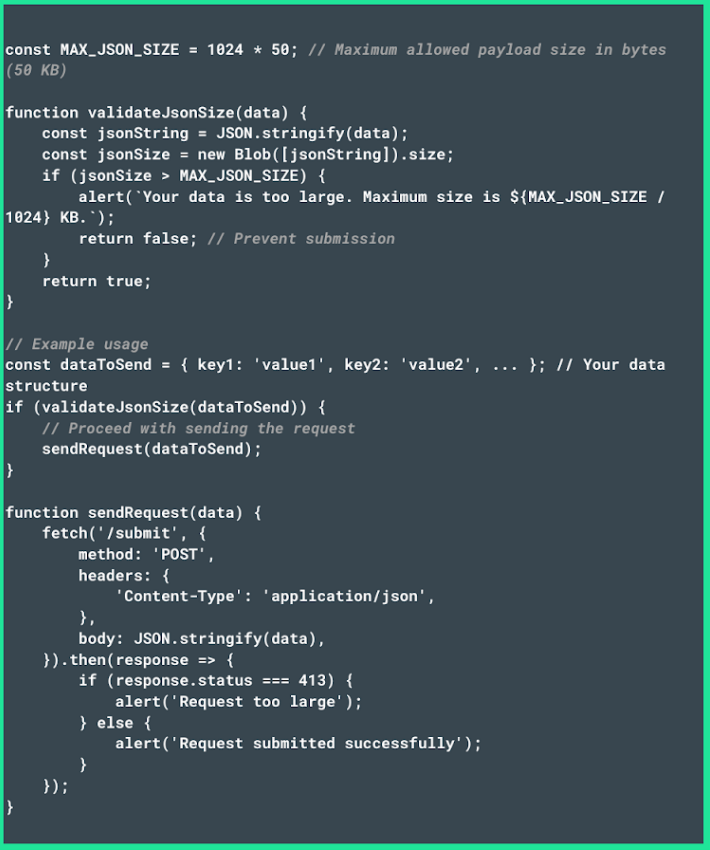
- Next, set a maximum size for JSON objects (in bytes) using MAX_JSON_SIZE, and enable client-side validation with the validateJsonSize function. For complex JSON objects, you can also measure their stringified size before sending them to prevent HTTP 413 issues after decompression.
- To further enhance client-side validation, ensure your application checks the depth and complexity of nested structures, as these can lead to oversized payloads. Start by setting a maximum depth (MAX_DEPTH), then implement the checkNestDepth function to enforce this limit.
.png)
By applying these measures, you ensure that excessively large payloads are blocked from reaching the server, safeguarding both the application’s functionality and the user experience.
Clear Documentation
In our experience, when working with software, it’s crucial to ensure that clients are fully informed of payload size limits, and understand the purpose of validation, as well as of other preventive measures.
Consequently, at Abstract API we prioritize providing clear documentation on payload size limits for our APIs. This helps foster client retention, as it helps prevent blocked requests, data loss, and workflow delays, while equipping users with the tools to handle HTTP 413 errors in a more dynamic and effective manner.
To fully leverage these benefits, documentation must be both accessible and easy to comprehend. While there’s room for innovation, effective documentation aimed at preventing HTTP 413 errors typically includes:
- Payload size limits, for both data requests and file uploads. They should be clearly stated, to ensure users are aware of the server’s capabilities.
- A discussion of the possible consequences of exceeding payload size limits, to showcase clients why they should avoid submitting oversized requests.
- Troubleshooting steps for addressing HTTP 413 errors. Ideally, they should include step-by-step guides, for diagnosing and resolving 413 issues.
- Practical examples and use cases, to demonstrate how to issue compliant requests, as well as alternative measures to circumvent size limitations.
- Additional resources, such as detailed information on HTTP status codes, troubleshooting guides, and FAQs.
By addressing these points, you can minimize the occurrence of HTTP 413 errors, build client trust, and encourage best practices among your users
Gracefully Handle HTTP 431 Errors
Last but not least, providing clear, comprehensive feedback ensures that clients can effectively manage HTTP 413 errors. Robust error handling measures also help prevent server overload by enabling users to address the causes of the HTTP 413 status code more efficiently
To gracefully handle HTTP 413 errors, it’s key to detect oversized payloads on both the server and client sides. When a request exceeds the server’s size limit, the server will return an HTTP 413 status code, along with a clear and actionable message that specifies:
- What caused the HTTP 413 error.
- How the client can fix it.
To implement this, you’ll need to configure both server-side and client-side error handling protocols.
- Start with server-side error handling.
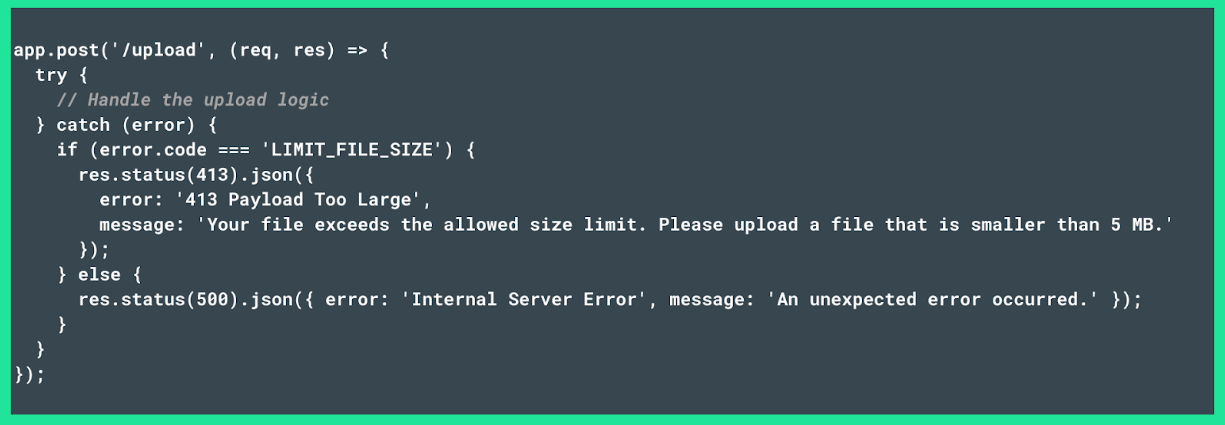
- If you are using Node.js (Express), run the following script to manage file uploads:
- For Nginx, use the following script:
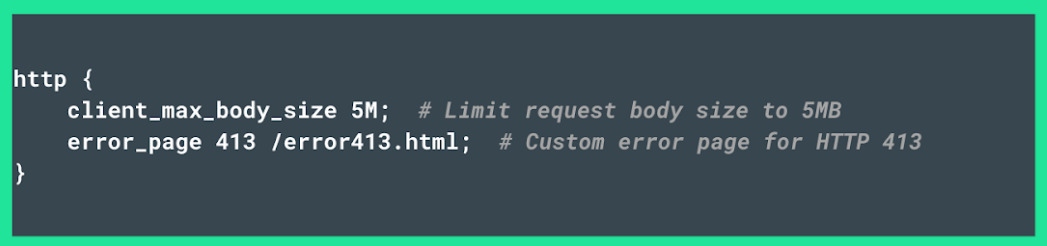
Both scripts ensure that a 413 Payload Too Large status code is triggered when a request hits the size limit. However, take into account that only the Node.js script instructs the server to return an accompanying message that helps users resolve the issue.
- On the other hand, for client-side error handling, ensure that the client can detect the HTTP 413 error and notify the user with a simple, plain-language message. You can use the following script to display the message: 'The file is too large. Please upload a smaller file', which can be customized to suit your specific needs.
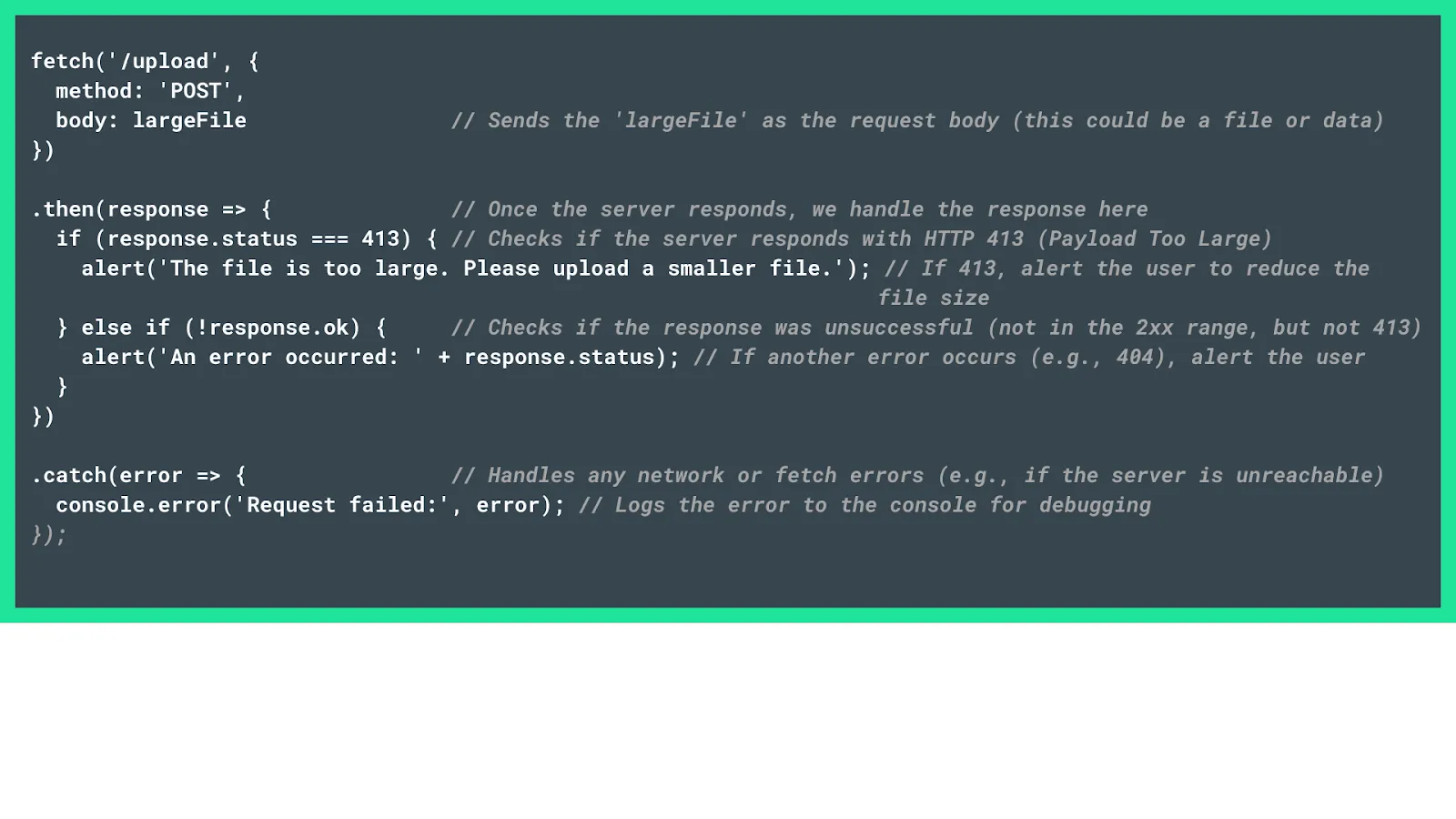
- Effective HTTP error management also requires clearly communicating how users can correct the issue. Make sure that the message includes specific, actionable steps, such as selecting files with an appropriate size or compressing the original request.
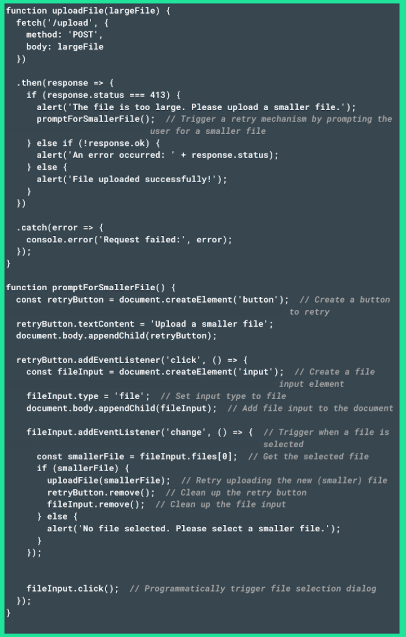
- Additionally, provide a retry mechanism, that allows the user to submit the request again after adjusting the data to meet the request size limits. The following approach will help you implement it:
- Finally, when multiple files are being uploaded and an HTTP 413 error occurs, each file should be handled separately, and the user should be informed about which file caused the error. Use the following script to achieve this:
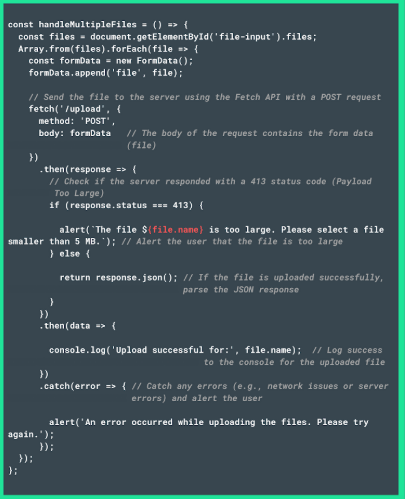
By applying these measures, you’ll ensure that users handle HTTP 413 errors seamlessly, preserving your API’s reputation and ensuring your software runs seamlessly.
Managing HTTP 413 Like a Pro
HTTP 413 status code indicates that the request payload is too large for the server to process. This can be caused by various factors, including submitting forms with overly large text inputs, oversized API requests, uploading excessively large files, or third-party service limitations, among others.
Receiving an HTTP 413 status code isn’t the end of the world—especially when you know how to handle it. If you've thoroughly read this article, you’ll already know there are several ways to ensure large requests are processed successfully, either from the client or server side.
The best part? These solutions can be applied both reactively, after encountering an HTTP 413 error, and proactively, as preventive measures to enhance user experience and greatly improve your software’s performance.
Given the impact HTTP 413 can have on a software’s functionality if not handled correctly, it’s only fair to conclude that understanding HTTP status codes is an essential skill any developer or API user should master. At least, that’s how we see it at Abstract API.
After all, not understanding HTTP status codes and how to manage them is like being blind and deaf to what the server is trying to tell us. And when navigating the digital landscape, we need all of our senses sharp and fully engaged.
HTTP 413 is only the tip of the iceberg. Explore our extensive documentation on APIs and best practices for data handling, and keep on honing your programming skills.
